
Under the hood
This page provides some technical details on how AIssistants work behind the scenes.
Feature and Prediction
These concepts are crucial when it comes to training an AIssistant and running it to update Jira issues.
Feature
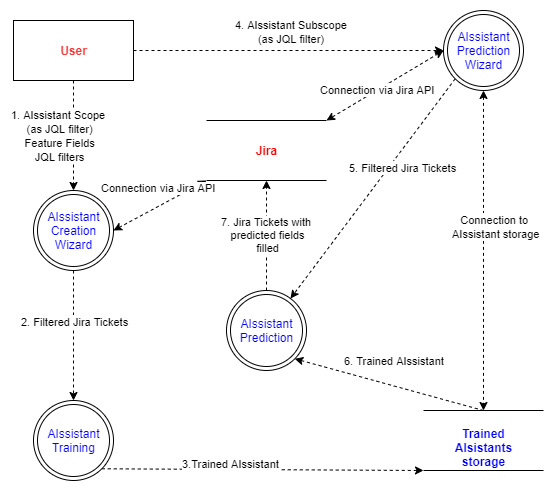
A feature is one column of data in your input set. Features are individual independent variables that act as the input in your system. Prediction models use features to make predictions. New features can also be obtained from old features using a method known as feature engineering. In other words, you can view one column of your dataset to be a single feature. Sometimes these are also called attributes. And the number of features is called dimensions.
Feature fields are fields in Jira issues used as an input by the AIssistant. Looking at the data in these fields, the AIssistant gets trained to understand what values Predicted fields should contain. When you run your AIssistant, Feature fields are looked at as a sample you have set, and based on their values Predicted fields are updated automatically.
Prediction
Prediction refers to the output of an algorithm after it has been trained on a historical dataset and applied to new data when forecasting the likelihood of a particular outcome, such as whether a customer will leave in 30 days or not. The algorithm will generate probable values for an unknown variable for each record in the new data, allowing the model builder to identify what value to use most likely .
The term "prediction" can be misleading. In some cases, it really does mean that you are predicting a future outcome, such as when you're using machine learning to determine the next best action in a marketing campaign.
Machine learning model predictions allow businesses to make highly accurate guesses as to the likely outcomes of an issue based on historical data, which can refer to all kinds of things – customer loss likelihood, possible fraudulent activity, and more. These provide the business with insights that result in tangible business value. For example, if a model predicts customer loss, the business can target the client with specific communications and outreach that will prevent the loss of that customer.
Last training accuracy
Suppose your AIssistant has finished training with 75% accuracy. Why not a 100%? There are some aspects that affect the training results.
You need some kind of confirmation that your model has got most of the training examples from the correct data, and that it does not contain a lot of "garbage", or in other words, it is low on bias and variance.
Validation
The process of deciding whether the results that define the hypothetical relationships between the variables as a description of the data are valid is called validation. Generally, an error estimation for the model is made after training; it is better known as evaluation of residuals. In this process, a numerical estimate of the difference in predicted and original responses is performed. It is also called the training error. However, this only gives us an idea about how well our model is doing on data used for training.
Cross validation
It is possible that the model is underfitting or overfitting the data. Hence, the problem with this evaluation technique is that it does not give an indication of how well the learner will generalize to an independent or unseen data set. Getting this idea about our model is known as cross validation.
A basic way to correct this involves removing a part of the training data and using it to get predictions from the model trained on the rest of the data. The error estimation then shows how our model performs on unseen data or the validation set.
The quality of the input data is an important aspect that you have to pay attention to, because of its influence on the final result.
When training on the set of existing Jira issues, an AIssistant will take 80% of them to analyze the logic of interconnections between fields used for decision making (Feature fields) and fields that should have been updated (Predicted fields). Armed with this knowledge, the AIssistant tries to predict Predicted fields of the remaining 20% without looking at them. Therefore, training accuracy is the percentage of issues that the AIssistant predicted correctly on this 20% of the dataset.
Overfitting
Overfitting is a modeling error that occurs when a function is too closely fit to a limited set of data points. This should be avoided. Overfitting the model generally takes the form of making an overly complex model to explain idiosyncrasies in the data under study. In reality the data studied has some degree of error or random noise in it.
Thus, trying to make the model conform too closely to slightly inaccurate data can infect the model with substantial errors and reduce its predictive power. As a result, this helps avoid the situation when the model adjusts to the data and reduces the prediction accuracy.